
 AI资讯网小编
AI资讯网小编 每天被海量资讯淹没,却找不到整理的头绪?五个步骤、两小时,这就是传统资讯整理的日常。
现在,AI改变了游戏规则:>一键完成从爬取到归档的全流程自动化,>高效到超乎想象!
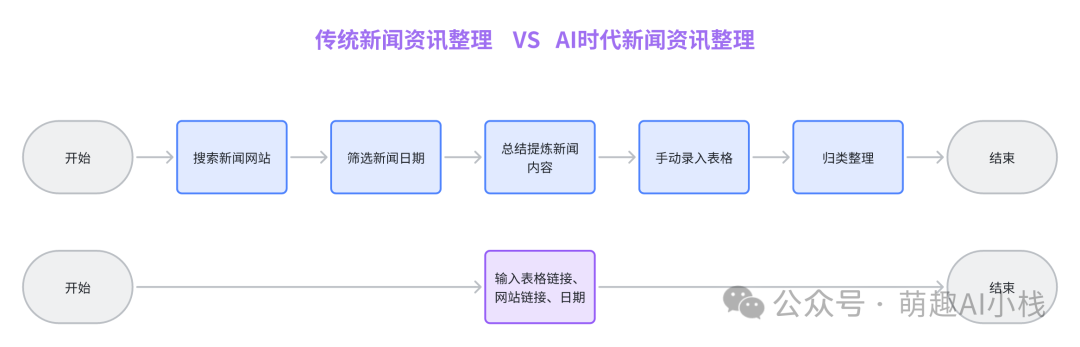 这一全新整理流程是如何实现的呢?小萌带大家一步步揭开>"DeepSeek+Coze+多维表格"的秘密,让你也能轻松驾驭数字时代的信息洪流。
这一全新整理流程是如何实现的呢?小萌带大家一步步揭开>"DeepSeek+Coze+多维表格"的秘密,让你也能轻松驾驭数字时代的信息洪流。
01
搭建逻辑
>老规矩,我们先来设计一下>搭建逻辑>,明确工作流的功能,实现一键新闻分类整理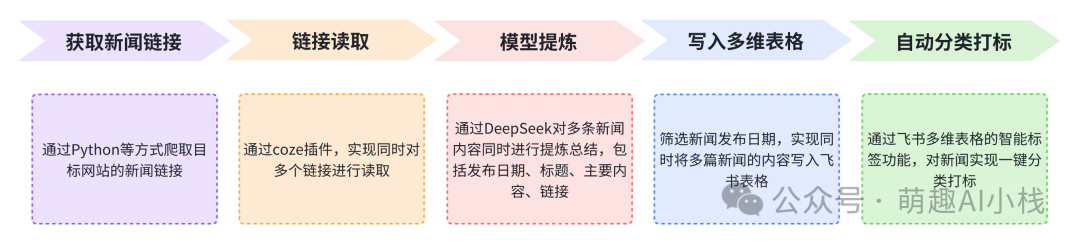
02
搭建步骤
>(保姆级教程,跟着一步步来,拥有个人新闻资讯整理助手不是梦!!)
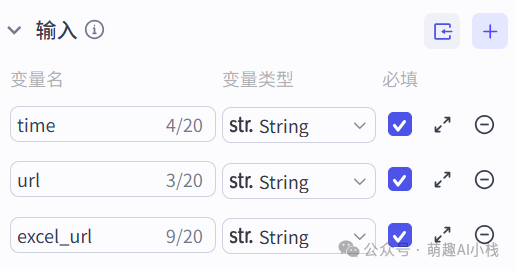
>1.开始节点
>设置输入变量为>新闻网站链接>、>发布日期>、>多维表格链接>,变量类型为“String文本”
>2.新闻链接获取节点
>(小萌建议大家认真阅读这一部分,对于自建coze插件、利用AI生成代码有一定的帮助~)
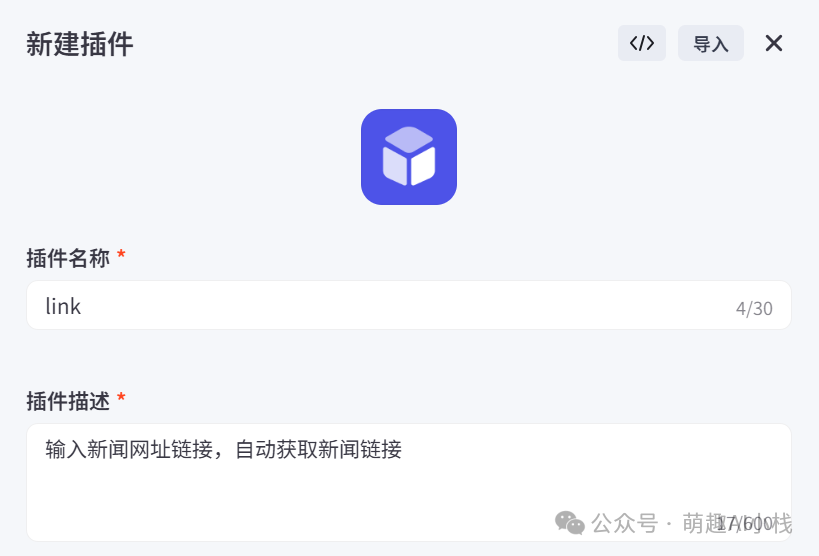
>我们希望在这一节点实现输入目标网站链接,实现一键爬取网站新闻的具体链接,但是在Coze的插件库里面并没有合适的插件,小萌决定>在Coze资源库自建一个插件>⚙
>①对插件的名称、描述、创建方式、运行环境进行设定
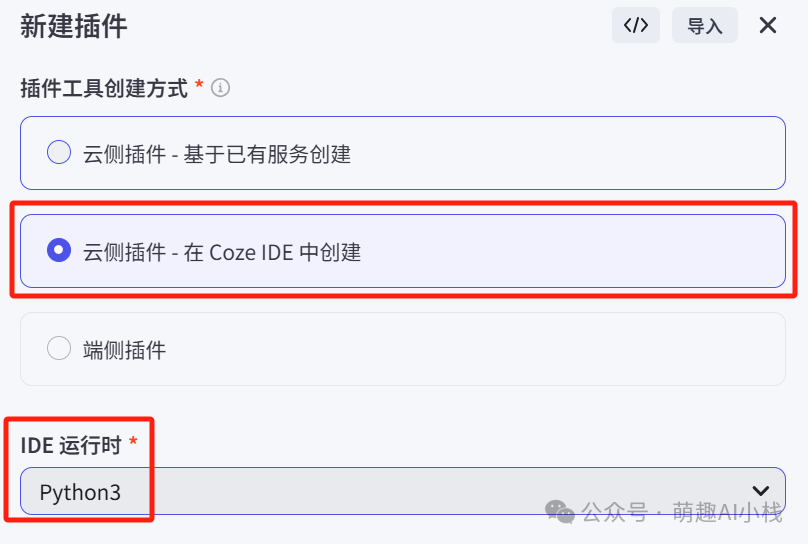
>②创建工具
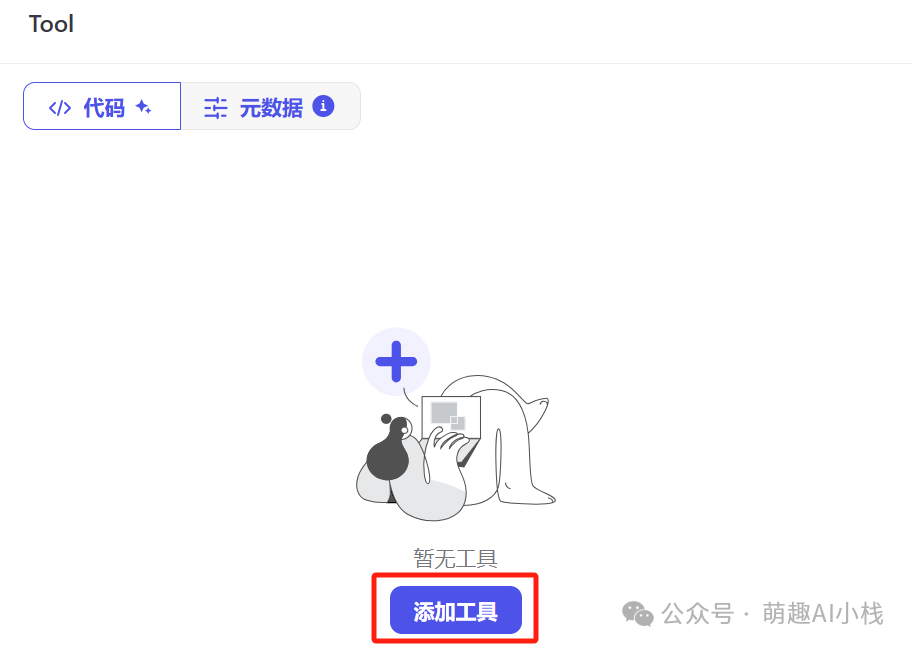
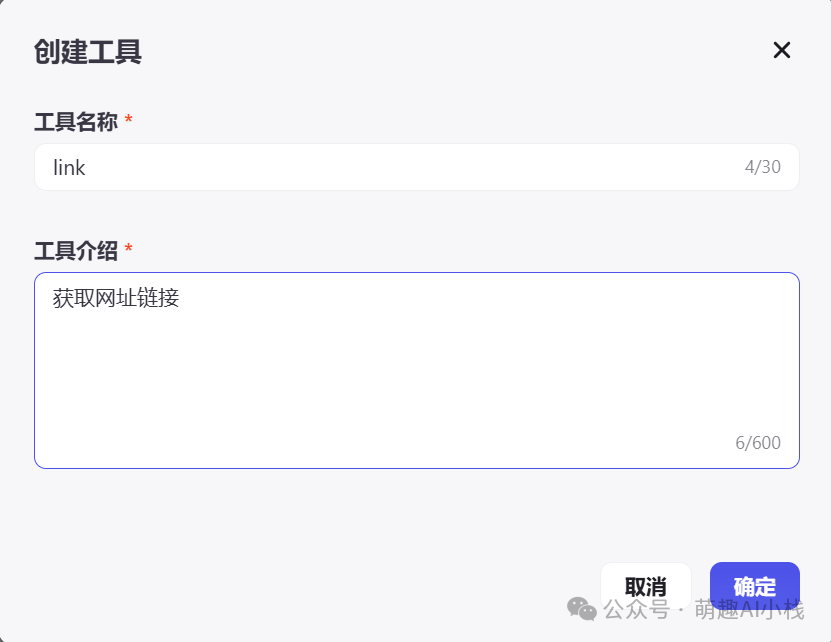
>得到了如下界面,可是小萌对代码是一窍不通😭
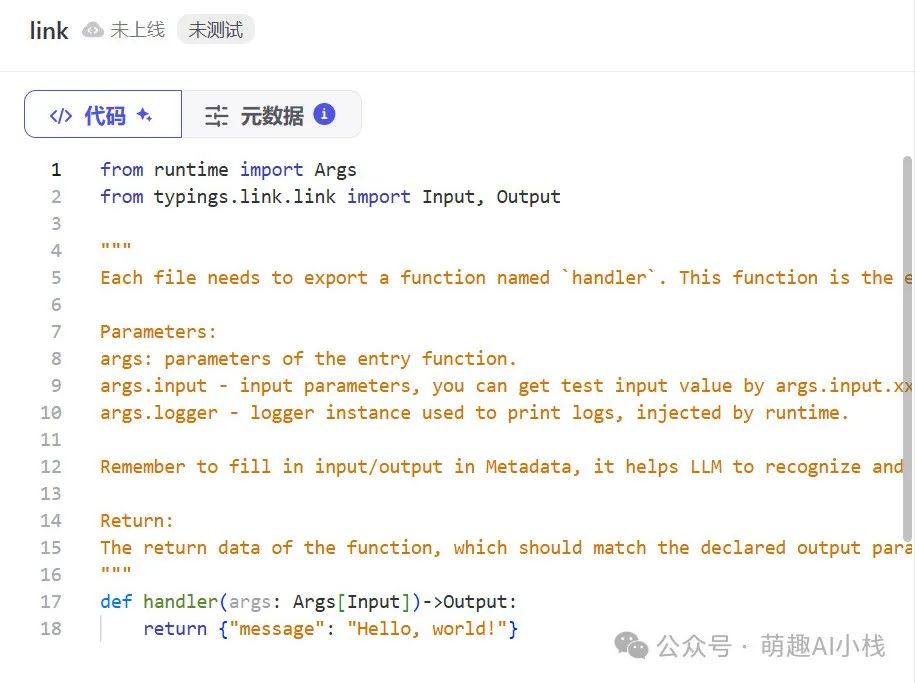
>忽然想起来之前和某大厂全栈工程师聊天,听说现在>AI写代码能力已经强的可怕了>😲
>AI写代码有多强呢?

>自从让AI写模板代码,腱鞘炎发作次数减少80%,终于有时间学新技术(和带薪拉屎)。
> > >—某不愿透露姓名的全栈工程师
>③编写代码
>作为编程小白,小萌>选择使用Claude3.5来帮助写代码>🥰,让我们一起看一下AI写代码的能力吧!输入我们需要这个插件实现的功能,并把Coze平台插件代码书写规范发送给Claude,五秒钟的时间就自动生成了代码,并告诉我们该如何去使用这段代码(非常细节好用,真的救了老命!!!)

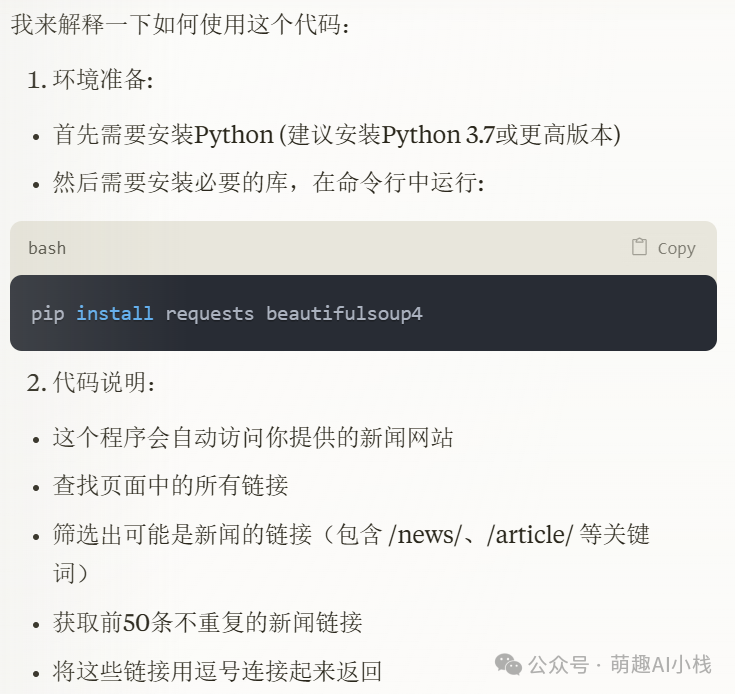
>将代码复制到Coze里面(>篇幅有限没办法完全展示代码,需要全部代码的可以后台私信免费获取哦~❤>),并按照Claude给的使用说明,安装依赖包>requests>和>beautifulsoup4
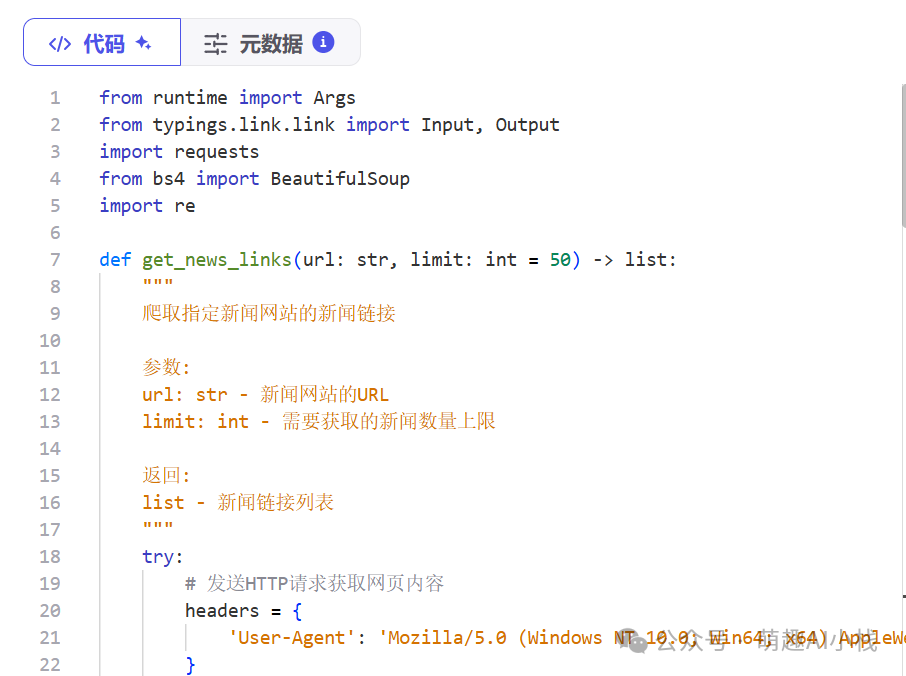
>④发布插件
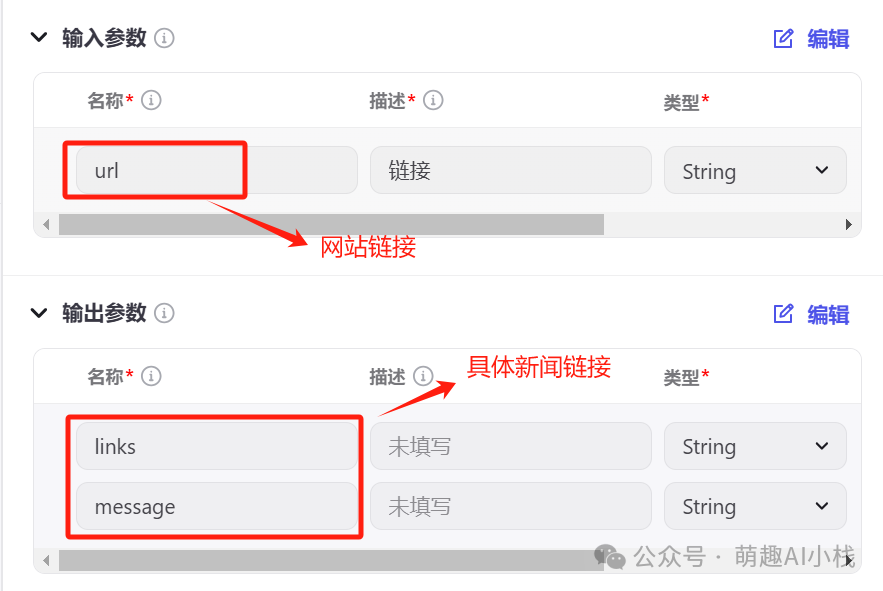
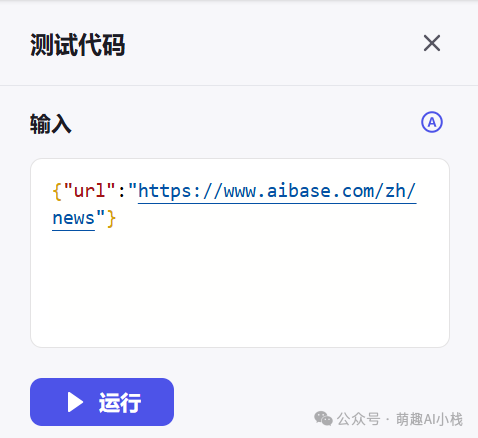
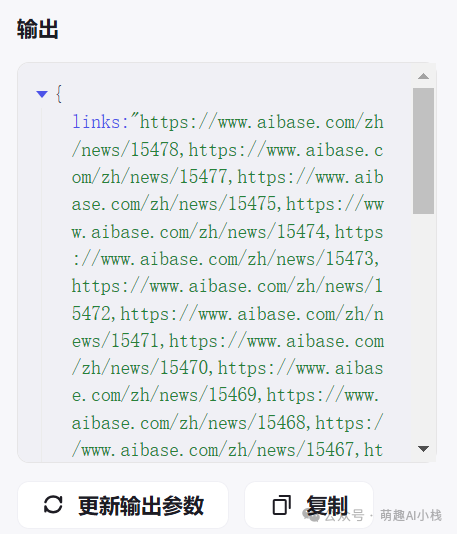
>设定>输入参数>和>输出参数>,选择一个网站网址输入,进行>试运行>,运行成功后点击发布,我们就可以在搭建工作流的时候直接插入这个插件啦😍
>⑤添加到工作流
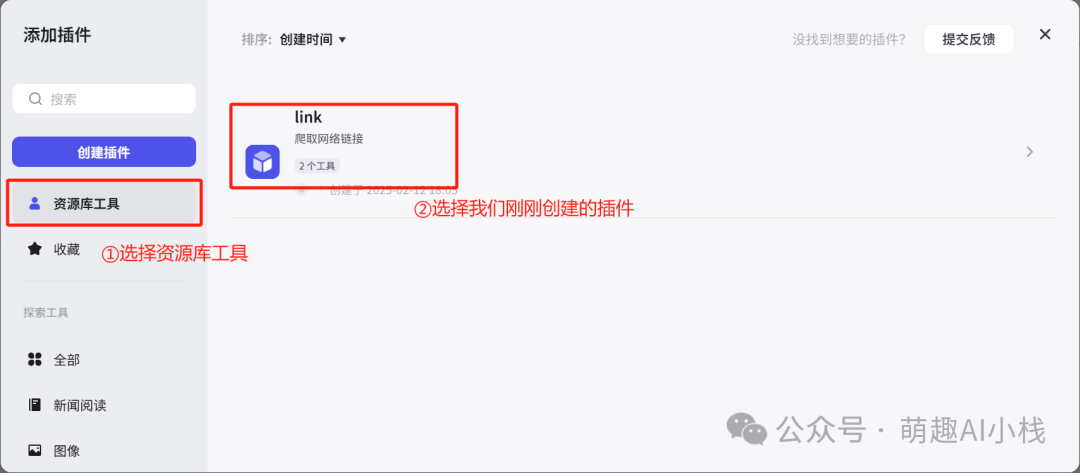
>返回我们工作流搭建界面,添加插件,选择>资源库工具>,找到我们刚创建好的插件添加,设置>输入参数为url
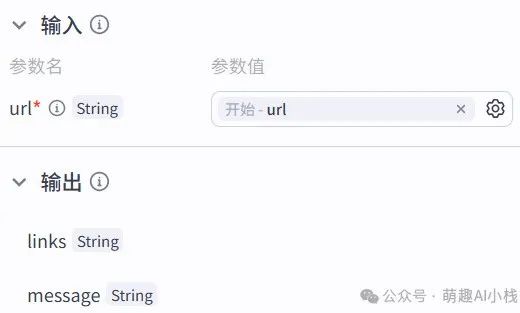
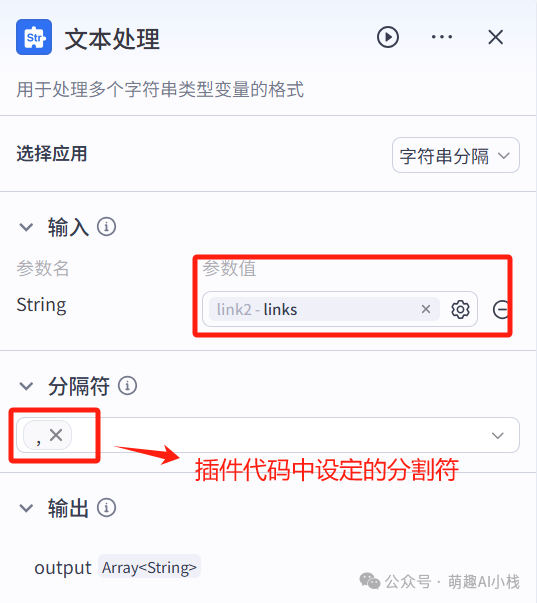
>3.文本处理节点
>在这一节点,需要将获取的多条链接转换成一个词组,因此添加文本处理节点,设定>输入参数>(新闻获取节点的输出)和>分割符

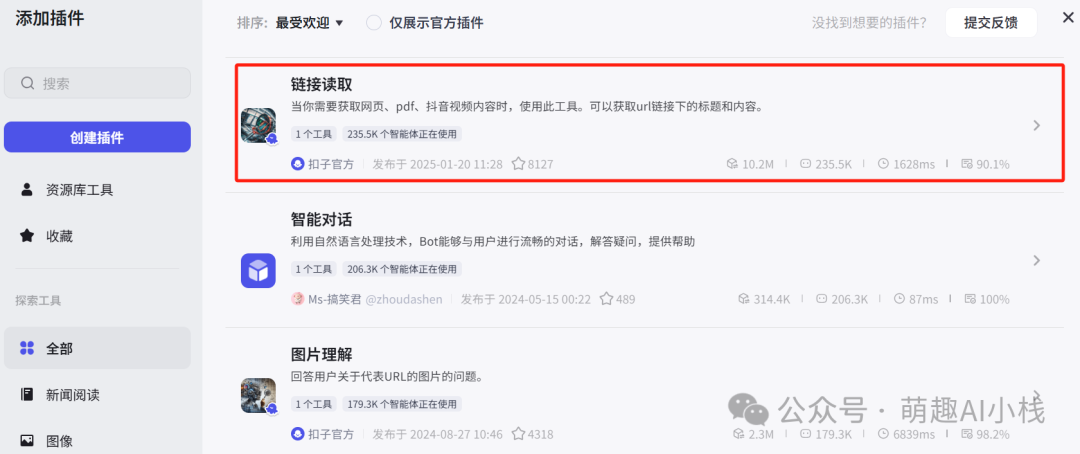
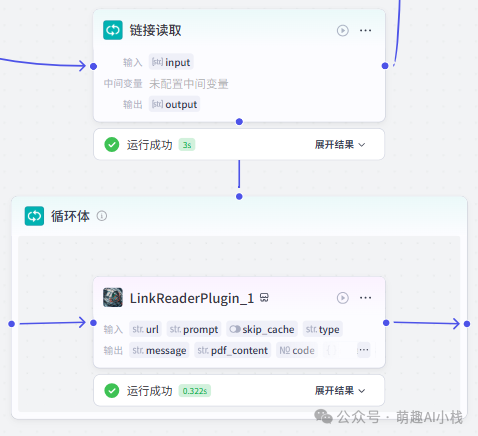
>4>.链接读取节点
>文本处理节点输出一组新闻链接(数量>10),插入>链接读取>插件生成文本内容,这里小萌发现该插件>批处理上限是10条链接>,因此要加入一个>循环体>(这里温馨提示一下,coze里>批处理是小循环,循环体是大循环>,当需要同时>处理内容较多时可以选择添加循环体哦>~)
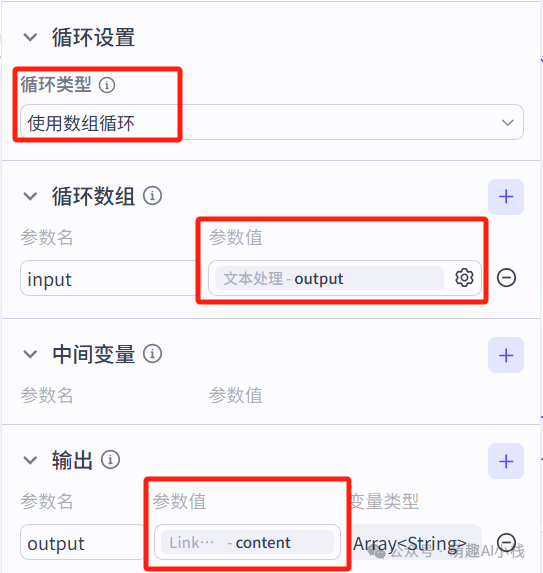
>5.新闻整理与总结节点
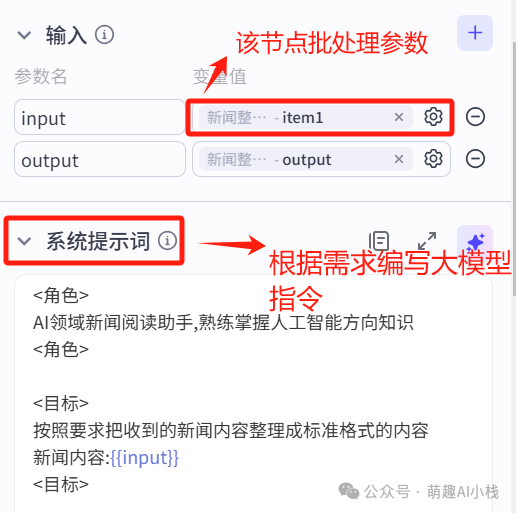
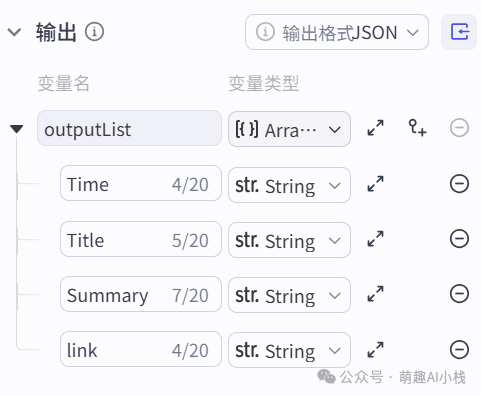
>添加大模型节点对新闻进行整理与总结,选择批处理,接入>DeepSeek模型>,设置批处理、输入参数名,根据需求编写大模型提示词(>需要完整提示词可以后台私信哦~>),设置输出变量为>发布日期>、>新闻标题>、>内容总结>、>新闻链接

>6.写入多维表格循环节点
>(该部分对于循环体建立原因和逻辑进行了略写,如有需要可以查看之前的文章《DeepSeek进阶玩法:Coze+DeepSeek打造一键论文阅读与分类整理工作流》)
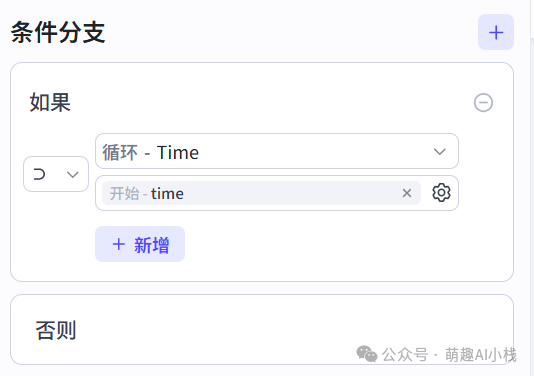
>①日期筛选
>添加>选择器>节点,对新闻发布日期进行筛选,只写入规定日期的新闻

>②Jason格式转换
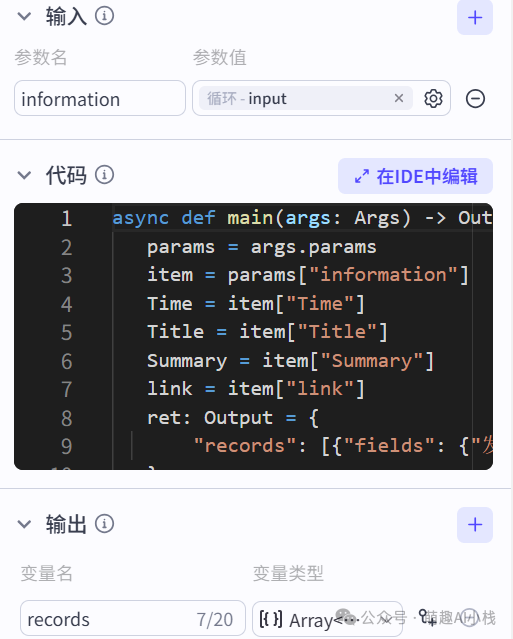
>在写入表格之前加入一个>代码节点>进行单次代码写入>,实现>Json格式转化>,保证其满足写入表格插件的输入格式要求,输出格式为Array<Object>
>③写入多维表格
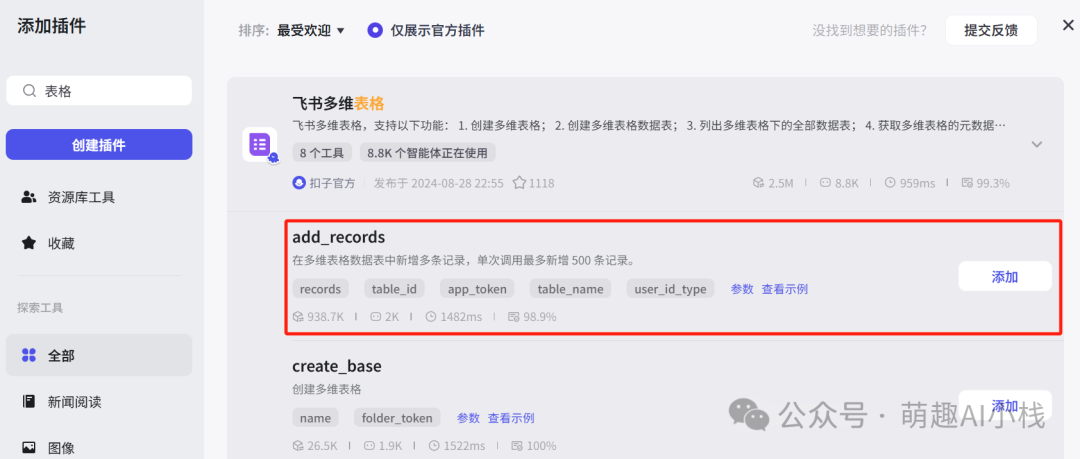
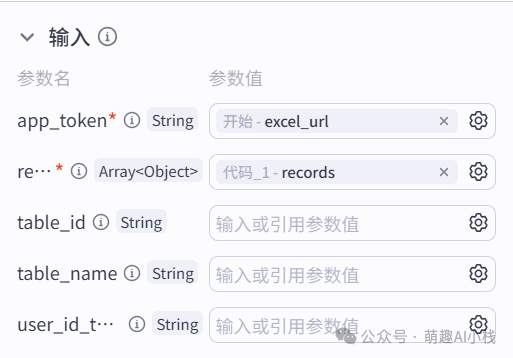
>添加Coze>官方插件>飞书多维表格->add_records
>④循环体建立
>由于需要同时处理多条新闻,加入循环体节点
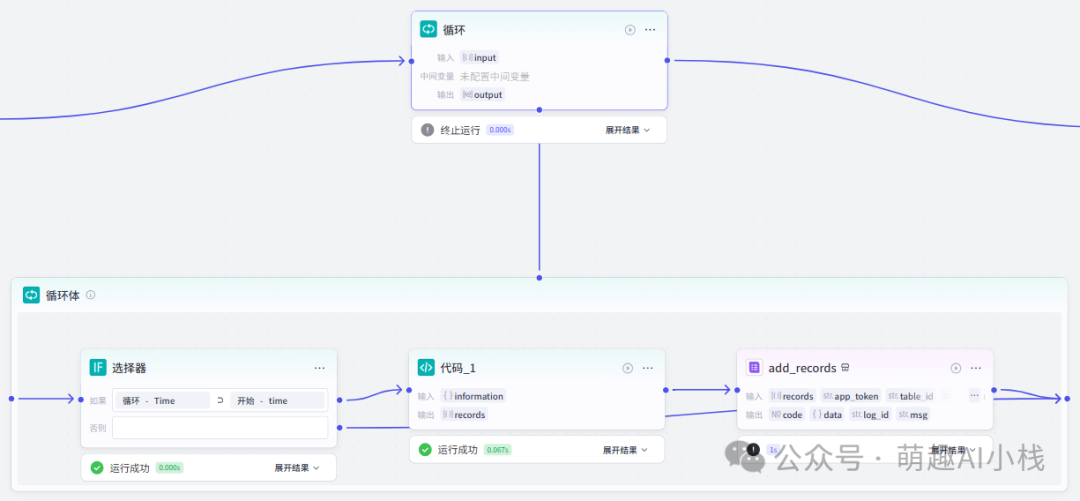
>7.结束节点
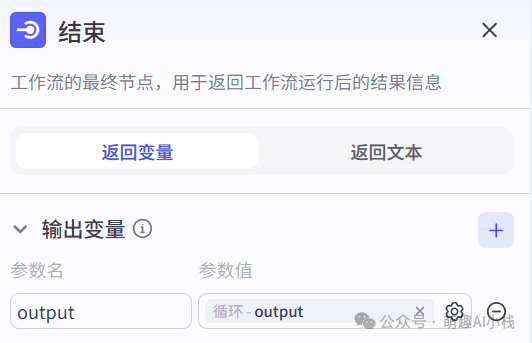
>整个自动获取新闻的工作流就大功告成啦!>(有耐心看到这里的你真的很棒哦❤)

>等等,你以为这就结束了?
>哒咩!!我们的>多维表格还没有派上用场>,请继续往下看,后面还有惊喜操作哦~

03
效果展示
>选择一个AI新闻网站,来测试一下这个新闻资讯整理工作流好不好用>输入表格网址、日期、网站网址,>一键点击试运行>,>工作流运行时间>仅仅一分钟>,最新的AI新闻已经都被整理到多维表格,大大解放劳动力,再也不用手动整理Excel表格了!!! >那多维表格如何使用呢?>飞书多维表格早就悄悄上线了很多>AI>功能>,>接入了满血版DeepSeek R1>,强大的让人感到陌生😱>我们在刚刚多维表格中再加入一列,选择>探索字段捷径>,发现有智能标签、DeepSeek等AI功能,这里小萌用>智能标签>做一下示范,手动添加>AI新闻分类>,一键为新闻进行打标
>那多维表格如何使用呢?>飞书多维表格早就悄悄上线了很多>AI>功能>,>接入了满血版DeepSeek R1>,强大的让人感到陌生😱>我们在刚刚多维表格中再加入一列,选择>探索字段捷径>,发现有智能标签、DeepSeek等AI功能,这里小萌用>智能标签>做一下示范,手动添加>AI新闻分类>,一键为新闻进行打标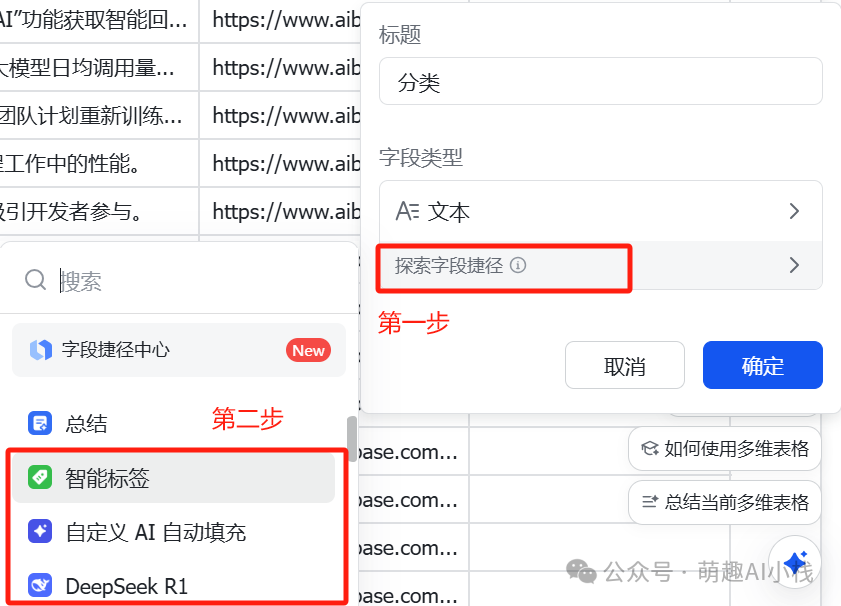
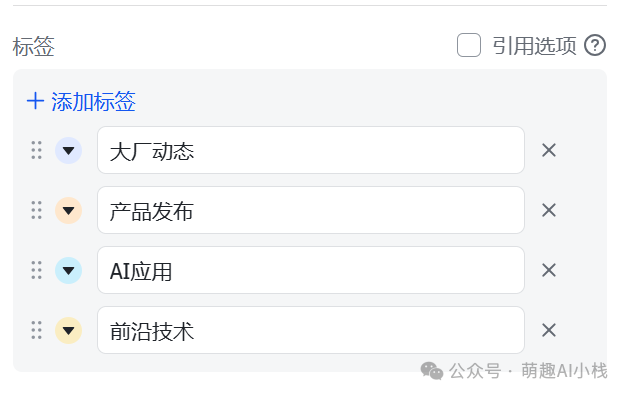 >智能标签迅速生成,小萌看了一下结果,准确率非常高,有了这个智能标签,再也不需要人工归类啦🥳
>智能标签迅速生成,小萌看了一下结果,准确率非常高,有了这个智能标签,再也不需要人工归类啦🥳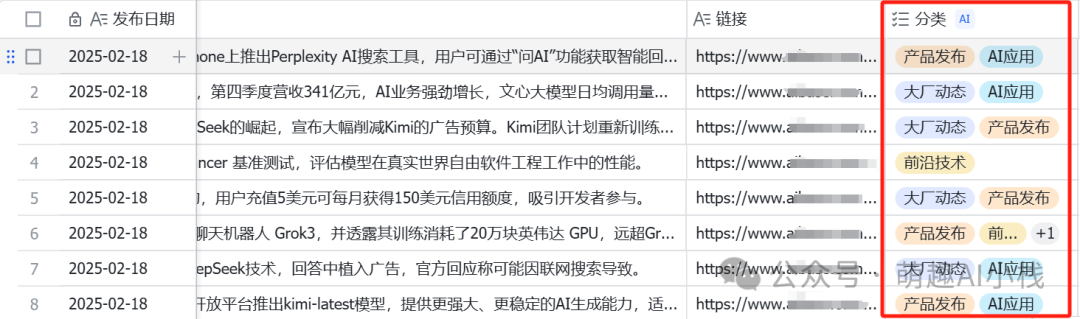 >信息爆炸时代,效率是核心竞争力。通过“>DeepSeek+Coze+多维表格>”的黄金组合,我们不仅解放了双手,更重新定义了信息处理的边界——>让工具为思考服务,让时间回归价值本身>。>如果你也曾为整理新闻资讯焦头烂额,不妨立即体验这套“懒人神器”。>点击「在看」或转发给团队伙伴,开启属于你的智能工作流。
>信息爆炸时代,效率是核心竞争力。通过“>DeepSeek+Coze+多维表格>”的黄金组合,我们不仅解放了双手,更重新定义了信息处理的边界——>让工具为思考服务,让时间回归价值本身>。>如果你也曾为整理新闻资讯焦头烂额,不妨立即体验这套“懒人神器”。>点击「在看」或转发给团队伙伴,开启属于你的智能工作流。转载请注明出处: CHATWEB
本文的链接地址: https://chatweb.com.cn/post-55.html
-

5 分钟教你用 DeepSeek + 讯飞星火实现 AI 数字人实时对话,老师必看!
2025/03/30
-
腾讯 ima 最强,没想到被这款AI工具彻底打脸!
2025/03/30
-
424万家!中国AI公司爆发式增长,水分也不少...
2025/04/19
-
用 AI 制作万物花开视频,绝了,和抄作业一样简单!
2025/03/30
-
近期又一热词:“元宝”是什么?
2025/04/19
-
豆包 AI 测评:你的智能聊天小助手!
2025/04/19
-
全网最全 Kimi 应用指南,高手必备!(建议收藏)
6天前
-
AI提示词设计:一篇文章带你从入门到精通,轻松掌握高效提示词技巧!
2025/04/19
-
高校教师的智能助手,全网最全Kimi使用指南
6天前
-
ChatGPT:全面了解这款AI驱动的聊天机器人
2025/04/19











 EMLOG
EMLOG
暂无评论