
 AI资讯网小编
AI资讯网小编

推理,是人类智慧的核心。
自 2025 年初以来,推理能力被各大公司赋予到各自大模型当中,试图让模型拥有人类的思维。
但依然存在明显不足,在处理复杂推理任务时,往往需要数十秒甚至更长时间才能做出回应,严重影响到我们使用体验。
直至今天,智谱给我们带来了新的突破,将推理模型交互体验上升到新的高度。
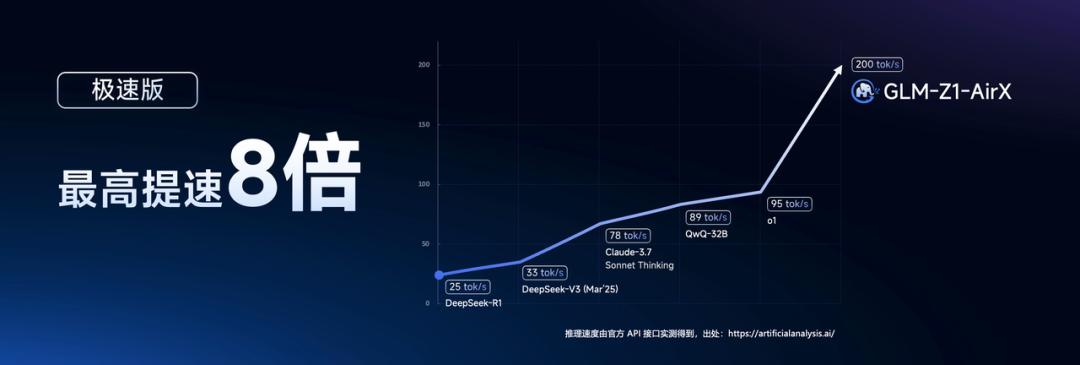
突破天际,开启新纪元智谱重磅开源 GLM-Z1-32B-0414 推理模型,推理速度最高可达 200 Tokens/秒,成为目前商业模型中速度最快。
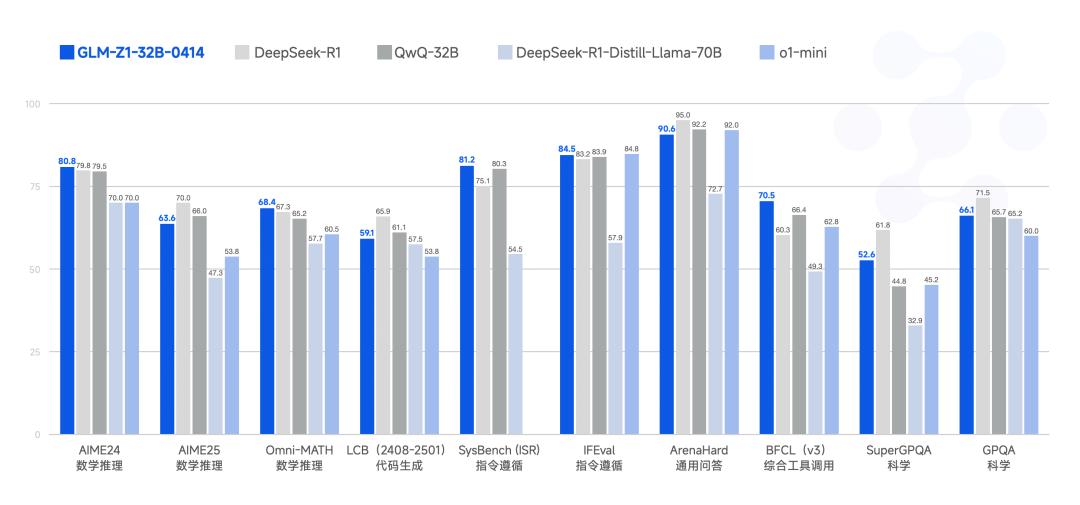
而且它仅仅凭借着 32B 参数,性能已能与拥有 671 参数的 DeepSeek-R1 相媲美。
并且在多项基准测试中,GLM-Z1-32B-0414 展现了较强的数理推理能力,能够支持解决更广泛复杂任务。
此外,模型还采用的是 MIT 许可协议开源,意味着我们可以直接免费用于商业。
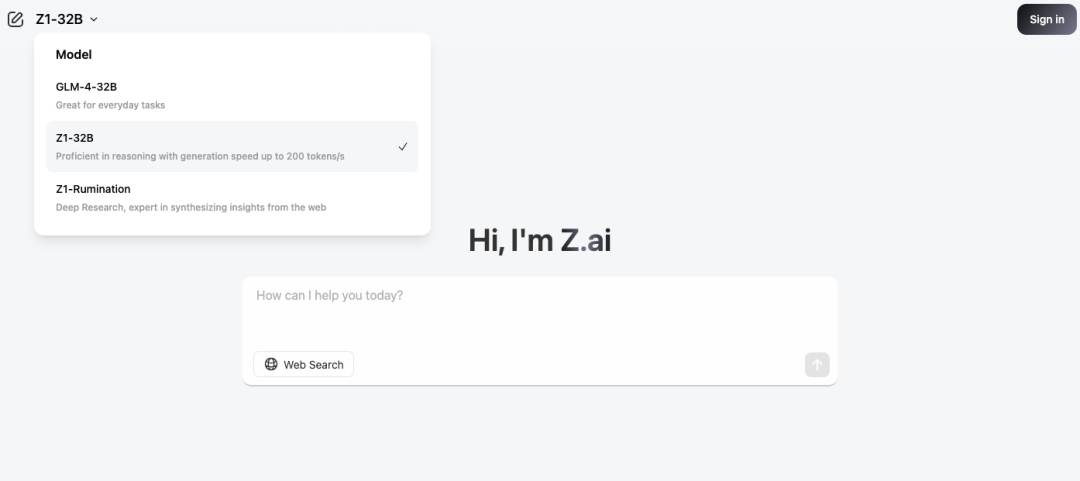
我们可以在智谱 BigModel 开发平台调用 API,价格仅仅是 DeepSeek-R1 的 1/30,也可以在 Z.ai 上免费体验。
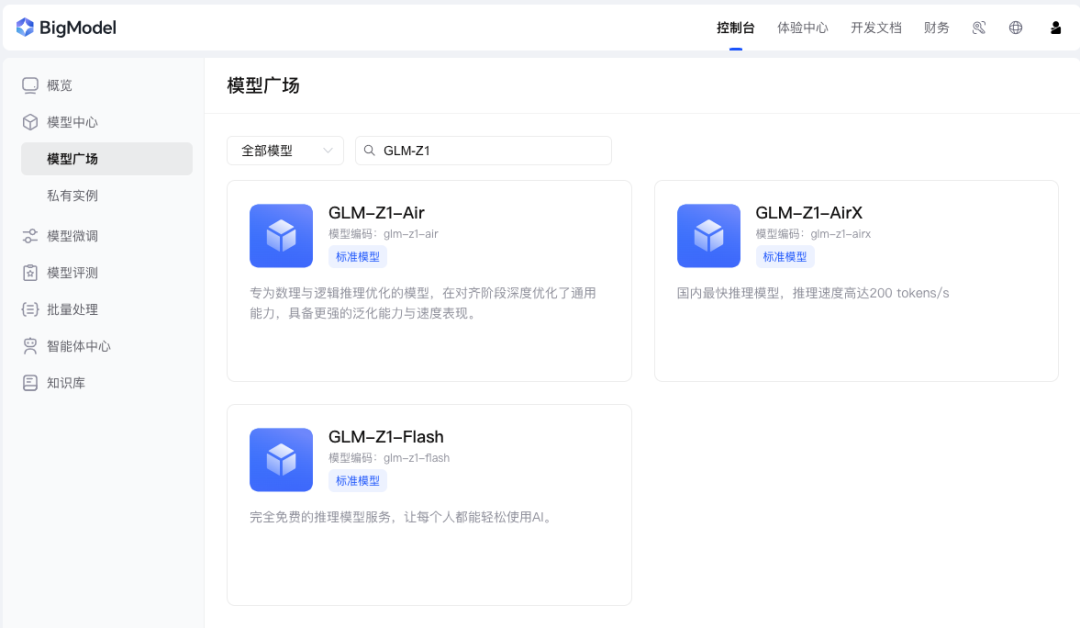
除此之外,还同步上线到智谱 MaaS 开放平台 (bigmodel.cn),面向企业和开发者提供 API 服务。
目前上线的推理模型有三个版本,分别满足我们不同场景需求:
-
GLM-Z1-AirX(极速版):定位国内最快推理模型,推理速度可达 200 tokens/秒,比常规快 8 倍;
-
GLM-Z1-Air(高性价比版):价格仅为 DeepSeek-R1 的 1/30,适合高频调用场景;
-
GLM-Z1-Flash(免费版):支持免费使用,旨在进一步降低模型使用门槛。
 经典哲学 AI 辩论
经典哲学 AI 辩论
下面就带大家直观感受 GLM-Z1-AirX 模型惊艳的速度,我将通过构建一个 “AI 辩论擂台” 应用, 并与 DeepSeek-R1 模型进行对比测试。
同时准备了一条经典测试推理模型的哲学问题:“博物馆着火,只能救一个,救猫还是救《蒙娜丽莎》?”
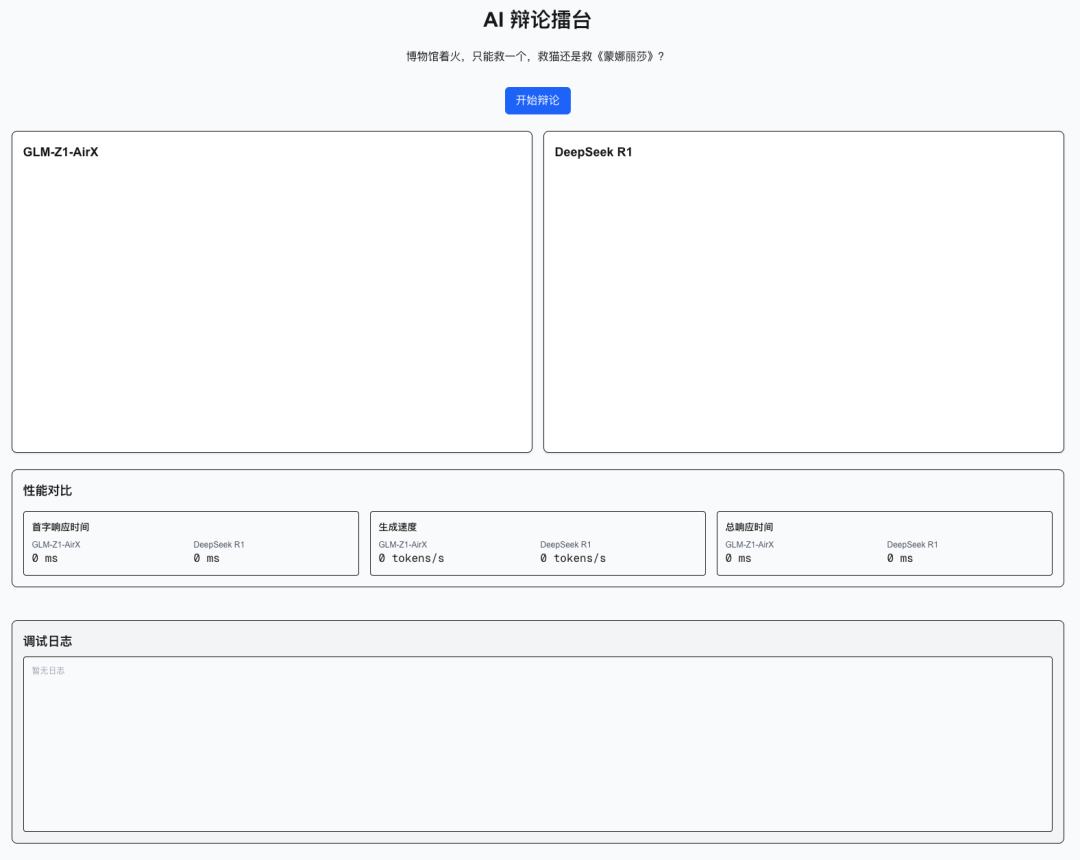
开始准备
首先我们前往智谱 BigModel 开放平台申请 API Key。
目前新用户能免费获得 2000 万 Tokens 的使用额度,足够我们进行充分测试。
申请地址:https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys
此外,我们还需要自行去申请 DeepSeek-R1 的 API Key。接着看下核心实现代码:
核心代码
模型 API 的调用
this.glmClient = new AIClient('https://open.bigmodel.cn/api/paas/v4/chat/completions',glmApiKey || '','glm-z1-airx');this.deepseekClient = new AIClient('https://api.deepseek.com/chat/completions',deepseekApiKey || '','deepseek-reasoner');
准备的 Prompt:
const prompt = '博物馆着火,只能救一个,救猫还是救《蒙娜丽莎》?' +'请从"救猫"的立场,给出三个有力论点支持你的选择。' +'请详细论证每个论点,包括价值观、实际考量因素和哲学依据。';
主要逻辑处理代码:
可以上下滚动的图片
实际测试过程一切准备好,启动运行应用,点击「开始辩论」按钮,即可在界面实时展示它们的输出。如下视频:
GLM-Z1-AirX 模型以肉眼可见的超高速输出,DeepSeek-R1 还在思考问题时,它就已经完成了完整的阐述。在调用模型之时,我记录下了所有关键信息,包括最终输出内容、首字响应时间、生成时间以及完成时间等等信息。
有了这些数据后,下面跟大家详细分析测试结果。
测试结果与数据分析响应时间对比
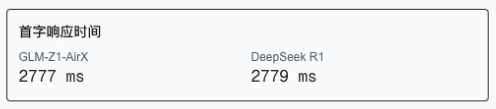
首字输出时间是作为户体验的关键指标。在实际测试中:
- GLM-Z1-AirX:收到请求后 2777ms 开始输出
-
DeepSeek-R1:收到请求后 2779ms 开始输出
有趣的是,两个模型在首次响应时间上几乎相同,都在 2.8 秒左右。
这表明首字输出不是 GLM-Z1-AirX 的核心优势所在,真正的差距在后续的生成速度上。
生成速度对比
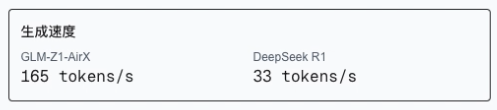
在这实际生成过程中,速度差异极为显著:
- GLM-Z1-AirX:实测平均维持 165 tokens/秒的生成速度
-
DeepSeek-R1:实测平均仅有 33 tokens/秒的生成速度
这里可以直观看出 GLM-Z1-AirX 的输出速度是 DeeSeek-R1 的 5 倍。
虽然没有达到官方说的 8 倍,但这个速度也足够给我们带来了出色的使用体验。
完成时间对比

对于相同任务的总完成时间差异更加惊人:
- GLM-Z1-AirX:仅用 17001ms (约 17 秒)
-
DeepSeek-R1:耗时 57860ms (近 58 秒)
DeepSeek-R1 完成同样内容所需的时间是 GLM-Z1-AirX 的 3.4 倍。
可想象一下,当你需要分析 10 篇论文时,GLM-Z1-AirX 可以在 3 分钟内完成,而其他模型则需要 10 分钟以上,直接让我们工作效率飙升。
思维深度对比由上数据分析可以看出,GLM-Z1-AirX 的生成和响应速度明显优于 DeepSeek-R1。
那么 GLM-Z1-AirX 是否以牺牲思维深度为代价换取的速度优势?
我们一起来看看,两个模型的输出内容:
GLM-Z1-AirX 分别从生命价值优先、现实决策和文明演进论三个论点进行论述,强调生命不可替代。

而 DeepSeek-R1 则从生命神圣体、在场责任以及文明存续三个论点进行论述。

从一个普通人的角度来看两者输出的结果,GLM-Z1-AirX 更加通俗易懂地论述了为什么选择 “救猫”,而 DeepSeek-R1 引用大量的哲学观点,直接看得一脸懵逼。
写在最后通过这次 “博物馆着火” 的哲学辩论测试,充分体现到 GLM-Z1-AirX 不仅思考得快,而且思考得深,给我们带来 “思考不打折” 的极速体验。
随着 GLM-Z1-AirX 这样的模型推出,相信不久,会有越来越多实时性的应用场景出现,如实时翻译对话、AI 伴侣等等,人们与 AI 的对话将变得更加自然流畅。
不禁遐想,当推理模型无限接近人类思考时,我们的生活又将会发生什么样改变?
值得一提的是,智谱 AI 团队的技术实力已获得全球认可!
刚看到 OpenAI 最新发布的 GPT-4.1 系列模型评测正采用的是智谱团队提出的 ComplexFuncBench 标准。
这意味着国产评测基准将会引领着全球大模型能力的评估方向。
转载请注明出处: CHATWEB
本文的链接地址: https://chatweb.com.cn/post-75.html
-

深藏不露!Kimi这8个隐藏用法,高手都偷偷收藏了,再不学习就晚了!(上)
6天前
-
开抢!腾讯官宣 28000 HC!
5天前
-
扣子(coze)实战 | 用coze一键打造自己的口播数字人,操作简单方便(包含coze网页登录、声音克隆、数字人制作)
2025/04/19
-
[AI工具箱] OneLine:一个由AI优化的时间线工具,如何帮你高效『吃瓜』?
5天前
-
扣子(Coze)怎么搭建工作流?
2025/04/19
-
我用AI「 高德 MCP+ cursor」 解决了日常最大难题“吃什么”!5分钟就搞定吃什么!
2025/04/19
-
28000个实习岗位,腾讯发起史上最大就业计划
5天前
-
华为电脑管家接入了四家大模型,却是“果篮式”的拼凑
2025/04/19
-
一文全懂:最牛AI公司OpenAI公司治理权斗背后的最创新股权设计
6天前
-
Kimi 16B胜GPT-4o!开源视觉推理模型:MoE架构,推理时仅激活2.8B
6天前


![[AI工具箱] OneLine:一个由AI优化的时间线工具,如何帮你高效『吃瓜』?](https://chatweb.com.cn//content/uploadfile/x_wxgzh/20250421/6805c4e998ffc.jpg)







 EMLOG
EMLOG
暂无评论