
转载请注明出处: CHATWEB
本文的链接地址: https://chatweb.com.cn/post-41.html


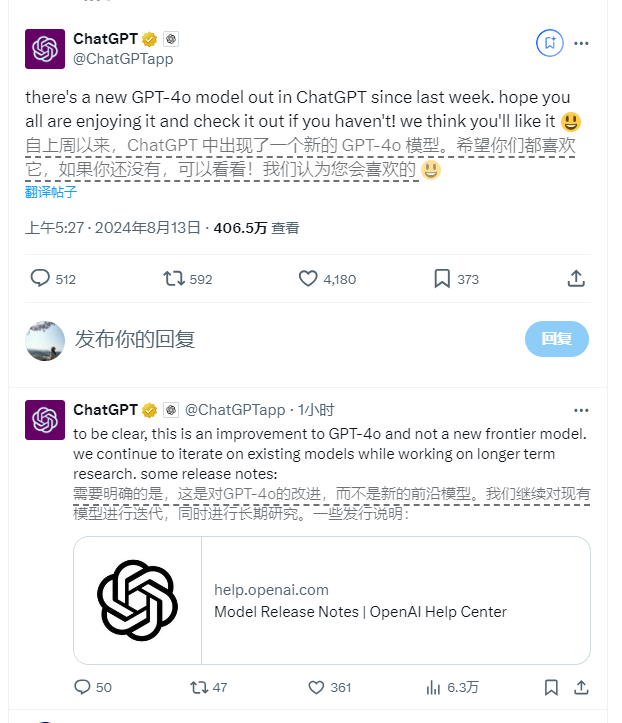
ChatGPT 在社交网络 X 上低调宣布已开始使用新的 GPT-4o 模型。官方表示:“自上周起,ChatGPT 中已采用了一个新的 GPT-4o 模型。我们希望你们都会喜欢它,如果还没体验过,不妨试试看!我们认为你会喜欢它。”
虽然 X 上的 ChatGPT 应用账户在发布帖子后没有立即提供更多详情,但 OpenAI 的内部消息人士透露,此次更新是基于用户的反馈进行的。
在随后的更新说明中,OpenAI 表示,他们引入了对 GPT-4o 模型的更新,并通过实验和用户反馈发现,用户更偏好这个新版本。虽然这并非一个全新的模型,但他们正努力探索更好的方法来衡量和传达模型在行为上的改进。
用户们很快注意到了新模型的一些特点,比如它似乎能进行更为细致的分步推理,并给出更为详尽的解释。不过,OpenAI 的一位发言人指出,模型的推理过程并未发生改变;ChatGPT 在描述其推理时主要是响应用户的特定提示。在正式公告之前,许多用户就已经感觉到 ChatGPT 的表现有了提升。
此外,用户还报告说 GPT-4o 在 ChatGPT 中的图像生成能力也得到了增强。虽然之前的 GPT-4 模型已经具备生成图像的能力,但这次的更新使得 GPT-4o 能够更高效地生成质量更高的图像。新模型不仅能处理文本,还能将像素转化为令牌,从而实现更准确、更真实的图像生成。
尽管大多数用户对这次更新表示欢迎,但也有一些人认为 OpenAI 应当更清晰地解释模型在用户体验和行为上的变化。一些用户甚至认为这次更新的变化不够显著,感觉有些表面化。
对于 ChatGPT 和 API 是否存在不同版本的 GPT-4o 这一问题,OpenAI 的发言人表示,他们经常在 ChatGPT 和 API 中进行小幅改进。他们会根据开发者的需求,在 API 中推出最佳的版本。
OpenAI 在其官方开发者账号中确认,新模型已在 API 中推出,开发者可以使用 "chatgpt-4o-latest" 来测试最新的改进。OpenAI 团队也正在积极回应用户和开发者关于这一更新的疑问。
转载请注明出处: CHATWEB
本文的链接地址: https://chatweb.com.cn/post-41.html
 AI资讯
(97)
AI资讯
(97)
AI资讯通常指的是关于人工智能领域的最新动态、技术进展、行业应用、市场分析以及相关政策法规等信息。这些资讯可以帮助人们了解人工智能的最新发展趋势,把握行业脉搏,促进技术交流与合作。简而言之,AI资讯是连接人工智能领域知识与大众认知的桥梁。
站长资讯
(4)
优化每一角落,打造全方位SEO网站体系。”这样的描述强调了分类的重要性,并暗示了通过SEO对网站进行全面优化的策略。
AI绘画
(7)
AI绘画是指利用人工智能技术创作视觉艺术作品的过程。这种技术通常通过深度学习和神经网络算法,模仿人类艺术家的风格和创作技巧,生成独特的图像和画作。AI绘画可以快速生成大量作品,为艺术创作提供新的可能性,同时也引发关于艺术创作本质和版权的讨论。简而言之,AI绘画是艺术与科技结合的产物,为传统绘画艺术带来了创新的视角和方法。
云服务器
(27)
域名资讯
(5)
科技资讯
(25)
科技简报是一种提供快速、简洁信息的新闻摘要,它通常包含当天最重要的新闻事件、市场动态、更新或其他关键信息。
AI应用
(20)
AI应用的短描述可以概括为:AI应用是利用人工智能技术,如机器学习和深度学习,来增强软件和硬件系统的能力,实现自动化、个性化服务和智能决策