
转载请注明出处: CHATWEB
本文的链接地址: https://chatweb.com.cn/post-60.html


多模态生成模型正在引领人工智能领域的最新潮流,这类模型致力于融合视觉与文本数据,创造出能完成多种任务的系统。这些任务涵盖了从根据文字描述生成高细节的图像到跨数据类型的理解与推理等多个方面,从而推动了更互动、更智能的AI系统的诞生,实现了视觉和语言的无缝结合。

在这个领域中,一个关键挑战是开发出自回归(AR)模型,使其能够根据文本描述生成高质量的图像。尽管扩散模型在这方面取得了显著进展,但AR模型的表现却相对滞后,尤其是在图像质量、分辨率灵活性以及处理各种视觉任务的能力方面。这一差距促使研究人员寻找创新方法来提升AR模型的能力。
目前,文本转图像生成的领域大多被扩散模型所占据,这些模型在生成高质量、视觉吸引力十足的图像方面表现出色。然而,像LlamaGen和Parti这样的AR模型在这方面却显得力不从心。它们往往依赖复杂的编码-解码架构,并且通常只能生成固定分辨率的图像。这种限制大大降低了它们在生成多样化、高分辨率输出方面的灵活性和有效性。
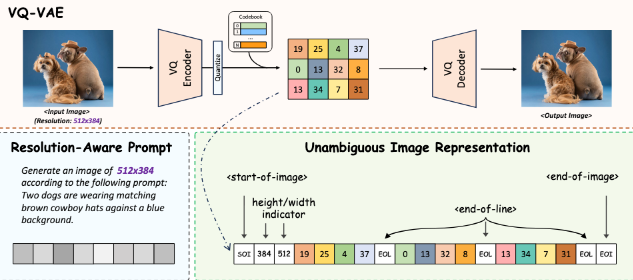
为了打破这一瓶颈,上海AI实验室和香港中文大学的研究人员推出了Lumina-mGPT,这是一种先进的AR模型,旨在克服上述限制。Lumina-mGPT基于解码器-only的变换器架构,采用了多模态生成预训练(mGPT)的方法。该模型将视觉与语言任务融入统一框架,目标是实现与扩散模型同等水平的逼真图像生成,同时保持AR方法的简便性和可扩展性。
Lumina-mGPT在增强图像生成能力方面采取了一种详尽的方法,其核心是灵活渐进的监督微调(FP-SFT)策略。该策略从低分辨率逐步训练模型生成高分辨率图像,首先在较低分辨率下学习一般的视觉概念,然后逐步引入更复杂的高分辨率细节。此外,该模型还引入了一种创新的明确图像表示系统,通过引入特定的高度和宽度指示符以及行尾标记,消除了与可变图像分辨率和纵横比相关的模糊性。
在性能方面,Lumina-mGPT在生成逼真图像方面显著超越了之前的AR模型。它能够生成1024×1024像素的高分辨率图像,细节丰富,与提供的文本提示高度一致。研究人员报告称,Lumina-mGPT仅需1000万对图像-文本进行训练,远低于LlamaGen所需的500万对图像-文本。尽管数据集较小,Lumina-mGPT在图像质量和视觉一致性方面依然超越了竞争对手。此外,该模型支持视觉问答、密集标注和可控图像生成等多种任务,展现出其作为多模态通才的灵活性。
其灵活且可扩展的架构进一步增强了Lumina-mGPT生成多样化、高质量图像的能力。该模型使用先进的解码技术,如无分类器引导(CFG),在提高生成图像质量方面发挥着重要作用。例如,通过调整温度和top-k值等参数,Lumina-mGPT可以控制生成图像的细节和多样性,帮助减少视觉伪影,提升整体美观。
Lumina-mGPT在自回归图像生成领域标志着重大的进步。这一由上海AI实验室和香港中文大学的研究人员开发的模型,成功架起了AR模型与扩散模型之间的桥梁,为从文本生成逼真图像提供了强有力的新工具。其在多模态预训练和灵活微调方面的创新方法,展示了AR模型潜在的变革能力,预示着未来将有更加复杂和多才多艺的AI系统诞生。
转载请注明出处: CHATWEB
本文的链接地址: https://chatweb.com.cn/post-60.html
 AI资讯
(97)
AI资讯
(97)
AI资讯通常指的是关于人工智能领域的最新动态、技术进展、行业应用、市场分析以及相关政策法规等信息。这些资讯可以帮助人们了解人工智能的最新发展趋势,把握行业脉搏,促进技术交流与合作。简而言之,AI资讯是连接人工智能领域知识与大众认知的桥梁。
站长资讯
(4)
优化每一角落,打造全方位SEO网站体系。”这样的描述强调了分类的重要性,并暗示了通过SEO对网站进行全面优化的策略。
AI绘画
(7)
AI绘画是指利用人工智能技术创作视觉艺术作品的过程。这种技术通常通过深度学习和神经网络算法,模仿人类艺术家的风格和创作技巧,生成独特的图像和画作。AI绘画可以快速生成大量作品,为艺术创作提供新的可能性,同时也引发关于艺术创作本质和版权的讨论。简而言之,AI绘画是艺术与科技结合的产物,为传统绘画艺术带来了创新的视角和方法。
云服务器
(27)
域名资讯
(5)
科技资讯
(25)
科技简报是一种提供快速、简洁信息的新闻摘要,它通常包含当天最重要的新闻事件、市场动态、更新或其他关键信息。
AI应用
(20)
AI应用的短描述可以概括为:AI应用是利用人工智能技术,如机器学习和深度学习,来增强软件和硬件系统的能力,实现自动化、个性化服务和智能决策